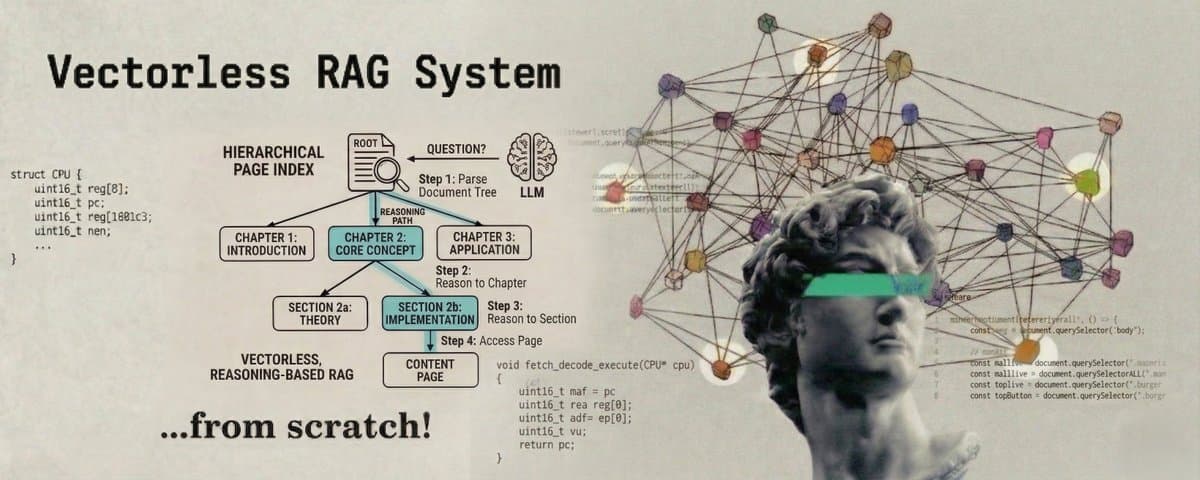
In this article we are going to build a Vectorless, Reasoning-Based RAG System using hierarchical page indexing, where a document is turned into a tree and an LLM reasons through that tree to find the answer. No embeddings. No similarity search.
This is very similar to how we search for information in real life. When you want to find something in a textbook, you do not read every page from the beginning. You open the table of contents, find the right chapter, look at the sections inside it, and go directly to the one you need.
PageIndex works the same way. You give it a document, it builds a tree from that document where each branch is a section and each leaf is the actual text, and then when you ask it a question, an LLM navigates that tree level by level to find the right answer.
Complete Code: https://github.com/vixhal-baraiya/pageindex-rag
(Don't forget to ⭐ star the repository if you found this helpful.)
The Plan
Here is the full plan before we write a single line of code.
Step 1: Parse the document into a hierarchical tree.
We send the document to the LLM and ask it to split the text into top-level sections. Then for each section that is long enough to be split further, we send it to the LLM again and get subsections. This gives us a multi-level tree. Short sections stay as leaves. Long sections become inner nodes with children.
Step 2: Summarize each node bottom-up.
We walk the tree from leaves to root. Each leaf node gets a short LLM-generated summary of its raw text. Each inner node gets a summary built from its children's summaries. The root ends up with a summary of the whole document.
Step 3: Save the index.
We serialize the tree to a JSON file. This is the index. We build it once and reuse it.
Step 4: Retrieve by walking the tree.
At query time, we start at the root. We show the LLM the summaries of all children and ask which one to go into. We move to that child. We repeat this until we reach a leaf. The leaf's raw text is our retrieved context.
Step 5: Generate the answer.
We pass the retrieved context and the question to the LLM and get our answer.
Architecture
Let's look at how data flows through the system.
Index Time (runs once)
Query Time (runs per question)
Now that we know what we are building and how all the pieces fit together, let's write the code.
Step 1: Set Up the Project
Create it:
Step 2: Define the Node (pageindex/node.py)
Every section of the document becomes a PageNode. It stores a title, raw text, a summary we generate later, and its children.
Step 3: Parse the Document (pageindex/parser.py)
We build the tree in two passes. First, we ask the LLM to split the whole document into top-level sections. Then, for any section long enough to be worth splitting further (more than 300 words), we send it back to the LLM and get subsections. Short sections stay as leaves. Long ones become inner nodes with children.
_segment is the helper that does one level of splitting. parse_document calls it twice: once for the whole document, and once per long section.
After this, short sections are leaves with content. Long sections are inner nodes with subsection children. All summary fields are empty at this point. The indexer fills those in next.
Step 4: Build Summaries (pageindex/indexer.py)
We traverse the tree post-order (children before parent). Each leaf summarizes its own content. Each inner node (like root, or any section that had subsections) gets a summary built from its children's summaries. Post-order guarantees every child has a summary before its parent needs it.
After build_summaries(root), every node in the tree has a meaningful summary.
Step 5: Save and Load the Index (pageindex/storage.py)
We serialize the tree to JSON so we only build it once.
Step 6: Retrieve by Tree Search (pageindex/retriever.py)
Starting at root, the LLM reads the children's summaries and picks the best branch. If that child is an inner node (it had subsections), we repeat at that level. We keep going until we hit a leaf. The while loop handles any depth.
Step 7: Tie It Together (main.py)
What the Index Looks Like
After running build_index, open index.json and you will see something like this:
Short sections stay as depth-1 leaves. Long sections (like "Shipping Options") became inner nodes with subsection children at depth 2. Retrieval navigates level by level until it hits a leaf.
Common Issues
The LLM keeps picking wrong branches. Your summaries are too vague. Try a stronger model in _summarize or add more detail to the prompt.
LLM segmentation cuts a section in a bad place. When parse_document runs on a long document, it sometimes splits mid-thought. Fix this by increasing max_tokens in the segmentation call, or break the document into ~3000-word chunks before sending each one.
Leaf content is very long. If a leaf has more than ~1500 tokens of content, lower SUBSECTION_THRESHOLD so more sections get split into subsections.
Complete Code: https://github.com/vixhal-baraiya/pageindex-rag
Don't forget to ⭐ star the repository if you found this helpful.
Keep building. Keep learning.